안녕하세요!
앞 전 시간에는 AI로 동물 10가지를 분류 했었는데요.
오늘은 연예인 닮은꼴 예측 프로그램을 AI로 만들어보는 시간을 가져보겠습니다!
📍 연예인 닮은 꼴 AI 예측 프로그램

본 프로그래밍은 구글 드라이브와 구글 Colab으로 제작하였습니다!
또 구글 드라이브에서 드라이브 마운트를 하고 저번에 만들었던 디렉토리와 같이 경로를 지정하였습니다.
%cd 'drive/MyDrive/Colab Notebooks/23.12.20딥러닝'📌 딥러닝 라이브러리 로드
# 라이브러리 로딩
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm # 진행율을 시각화 해주는 도구 (파이썬에서 몇 번 반복했는지 쉽게 볼 수 있음)
from tensorflow.keras.utils import image_dataset_from_directory # 폴더에서 이미지를 불러오는 도구
# 훈련/평가용 데이터 분리 함수
from sklearn.model_selection import train_test_split # 훈련/평가용 데이터 분리 함수
# 이미지 특징을 추출하는 도구
from tensorflow.keras.applications import InceptionV3 # 이미지 특징을 추출하는 도구
# 신경망모델 import
from tensorflow.keras.models import Sequential # 딥러닝 모델의 뼈대
from tensorflow.keras.layers import Dense # 뉴런의 묶음을 표현하는 클래스 뉴런을 이용해서 모델을 만들때 성능은 좋지만 최대한 가볍게 만들어야함
from tensorflow.keras.callbacks import EarlyStopping # 조기학습 중단 비효율으로 시간을 낭비하지 않게 함
from tensorflow.keras.callbacks import ModelCheckpoint # 모델자동저장 과대적합을 피하기 위해 미리 자동으로 저장
# 예측과 평가
from tensorflow.keras.models import load_model # hdf5 포멧의 모델파이를 로딩하는 함수
from sklearn.metrics import classification_report # 분류 평가지표 확인 함수
from tensorflow.keras.optimizers import Adam #Adam의 learning rate를 수정가능함
from tensorflow.keras.preprocessing.image import ImageDataGenerator# 이미지 자체에 효과를 주는 도구연예인 닮은꼴 예측을 하기 위해 tensorflow를 사용하였고, 라이브러리는 위와 같이 import 해주었습니다!
📌 데이터 수집하기
# 네이버 이미지 크롤링 JavaScript
let imgs = document.querySelectorAll(".image_tile_bx img")
let imgArrData = new Array();
for(i=0; i<imgs.length; i++){
let s = imgs[i].src;
if(s=='') s = imgs[i].getAttribute('data-src');
imgArrData.push(s);
}
var blob = new Blob([imgArrData], {type: "text/csv"});
var url = window.URL.createObjectURL(blob);
var anchor = document.createElement("a");
anchor.href = url;
anchor.download = "demo.csv";
anchor.click()먼저 네이버 이미지에서 원하는 연예인을 검색해 줍니다.
다음 F12로 개발자 도구를 열고 콘솔 창에 코드를 넣고 엔터 하면 csv 확장자의 엑셀 파일이 생성되는데 이미지 파일의 URL이 담겨있어요.
저는 다른 연예인도 검색해서 총 3명을 학습 시켜보겠습니다!
📌 CSV 파일로 사진 다운로드
# jupyter notebook 사용
import pandas as pd
import urllib.request as req
from tqdm import tqdm
# .T는 가로가아닌 세로로 바꾸는 용어
pdyeo= pd.read_csv("./data/demoyu.csv", header=None, ).T
for index, url in tqdm(enumerate(pdyeo.values)) : #enumerate 반복문을 돌리면서 인덱스도 붙이는 함수 .values 는 url만 가져옴
# print(index, url[0])
try:
filename = f'./data/face/yeo/{index}.jpg'
req.urlretrieve(url[0],filename)
except :
continue # 예외 발생시 계속해서 진행
csv 파일을 jupyter notebook에서 다운로드합니다.
data 폴더와 연예인 이름 폴더를 따로 만들고 사진을 저장했습니다!
저는 여진구, 강하늘, 송중기 세 명의 연예인분들로 만들었어요.
📌 데이터셋 만들기
total_data = image_dataset_from_directory(
directory = "./data/face/",
labels = "inferred",
label_mode = "categorical",
color_mode = "rgb",
image_size = (224,224)
)
X_data = []
y_data = []
for img, label in tqdm(total_data.as_numpy_iterator()):
X_data.append(img)
y_data.append(label)
X_numpy = np.concatenate(X_data)
y_numpy = np.concatenate(y_data)
X_numpy.shape , y_numpy.shape
np.savez("./data/face.npz", X=X_numpy, y=y_numpy)모델을 학습시키기 위한 데이터 셋을 만들어 줍니다.
- X_data 학습용
- y_data 정답용
📌 모델 만들기
# 저장된 데이터셋 로드
npz_data = np.load("./data/face.npz")
X_numpy = npz_data['X']
y_numpy = npz_data['y']
X_numpy.shape, y_numpy.shape
plt.imshow(X_numpy[1].astype("int64")) # 사진 확인
gen= ImageDataGenerator(rotation_range=90,
horizontal_flip=True,
zoom_range=5.0,
width_shift_range=10.0)
# 효과를 만들고 face_model.fit(gen.flow(X_train, y_train) 으로 튜닝을 한다.
# validation_data = (X_test, y_test))도 넣어줘야함
# 학습용 데이터 나누기
X_train,X_test,y_train,y_test = train_test_split(X_numpy, y_numpy,
test_size=0.2,
random_state=1219)
# 이미지 특징 데이터 전처리
ImageEmbedding = InceptionV3(
include_top = False,
weights="imagenet",
input_shape=(224,224,3), # 이미지 특징을 추출할 데이터의 크기(모양)
pooling='avg'
)
# 딥러닝 모델 생성
face_model = Sequential() # 뼈대 생성
face_model.add(ImageEmbedding) # 이미지 특징추출 도구 연결
face_model.add(Dense(units=128, activation='relu')) # Dense -> 뉴런의 묶음 units에 숫자 바꿔도됨
face_model.add(Dense(units=256, activation='relu')) # Dense -> 뉴런의 묶음 원하는 만큼 뉴런 생성
face_model.add(Dense(units=128, activation='relu')) # Dense -> 뉴런의 묶음
face_model.add(Dense(units=3, activation='softmax')) # Dense -> 뉴런의 묶음 마지막은 같아야함
# 모델 컴파일
face_model.compile(loss="categorical_crossentropy", # 모델의 잘못된 정도(오차)를 측정하는 도구
optimizer=Adam(learning_rate=0.0001), # 모델 최적화 도구 -> 경사하강법 알고리즘
metrics=['accuracy']) # 모델의 평가지표)
# 모델 조기 학습완료
early = EarlyStopping(monitor="val_accuracy",
patience=5)
# 모델 자동저장
model_path = "./face_model/face-{epoch:02d}-{val_accuracy:.2f}.hdf5"
mdckp = ModelCheckpoint(filepath = model_path,
save_best_only=True,
monitor="val_accuracy")
# 모델 학습
h = face_model.fit(X_train, y_train,
validation_split = 0.2,
epochs=100,
callbacks=[early,mdckp],
batch_size=16)긴 코드 지만 모델을 학습하면서 주석을 읽어보시면 될 것 같아요.
조기 학습이 끝나면 제일 높았던 모델이 저장이 되어 있어요.
그 모델을 가지고 예측을 할 거에요.
📌 닮은꼴 예측하기
# 제일 좋은 모델 로드
best_face_model = load_model("./face_model/face-13-0.80.hdf5")
# 예측하기
pre = best_face_model.predict(X_test)
print(classification_report(y_test.argmax(axis=1),
pre.argmax(axis=1)))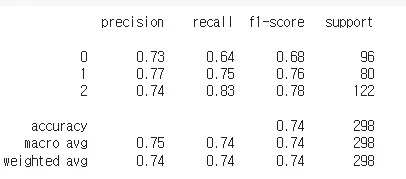
예측률과 재현율이 비슷하게 잘 나온 것 같지만 아주 정확하게는 예측이 안 되는 것 같아요.
데이터양을 늘리면 학습이 더 잘 될 것 같아요.
📌 실제 사진으로 예측하기
import gradio as gr
# 예측 알고리즘 함수
def my_predict(input_img) :
input_img = input_img.reshape(1,224,224,3) # 1장의 사진을 4차원으로 만들어줌
pre = face_model.predict(input_img).flatten() # 모델예측
class_names = ['gang', 'song', 'yeo']
return {class_names[i]: float(pre[i]) for i in range(3)}
demo = gr.Interface(my_predict, # 연결된 함수의 return 값을 화면에 연결
inputs= gr.Image(shape=(224,224)), # 생성될 입력 인터페이스 설정
outputs=gr.Label(num_top_classes=3)) # 생성될 출력 인터페이스 설정
demo.launch(share=True)이 코드는 방금 만들었던 모델을 가지고 웹페이지에서 실제로 사진을 예측하는 화면을 만드는 코드예요.
서버가 계속 켜져 있다면 다른 사람과 공유도 할 수 있고 실제 사진을 가지고 예측하는 거라 체감이 확 올 거예요.
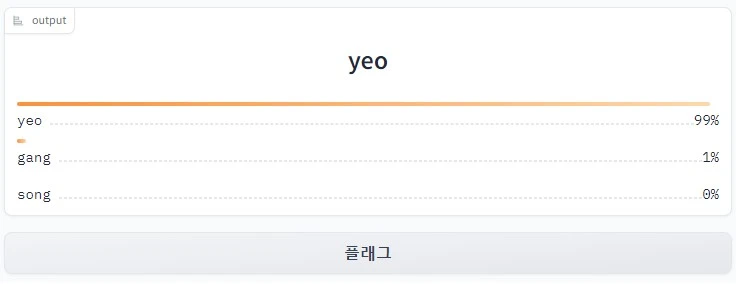
여진구 씨의 사진으로 예측을 해본 결과 99퍼센트로 예측을 할 수 있었습니다!
주변 사람들에게 연예인 닮았다고 들어보신 분들이 있다면 기계가 정말 인정해 주는지 확인해 보세요!
그럼 다음에도 좋은 정보로 찾아오겠습니다!