안녕하세요!
지난번엔 앙상블에 대해 소개해 드렸었는데, 오늘은 앙상블 중에서 배깅과 부스팅 모델의 종류에 대해 소개해 드리겠습니다!
📍 배깅, 부스팅 모델의 종류

앙상블에 간단한 설명을 드리자면 단일 모델에 비해 높은 성능과 신뢰성을 얻을 수 있고 데이터의 양이 적지만 충분한 학습 효과를 거둘 수 있는 장점을 가지고 있어요!
모델의 종류는 배깅의 랜덤 포레스트, 부스팅의 GradientBoosting, Ada Boosting 등이 있습니다.
📌 랜덤 포레스트
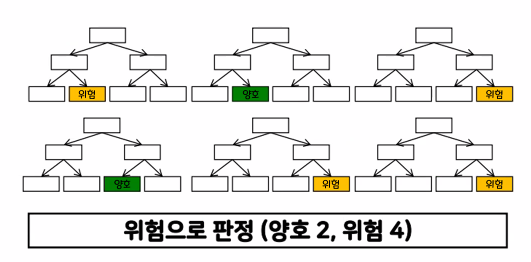
- 여러 개의 결정 트리 모델로 예측한 값을 투표를 통해서 최종 선택하는 배깅의 대표적 모델
- 다수의 의사결정 트리의 의견이 통합되지 않는다면 -> 투표에 의한 다수결의 원칙을 따른다 -> 앙상블 방법
- 장점 : 실제 값에 대한 추정 값 오차 평균화, 분산 감소, 과적합 감소
주요 매개변수(hyperparameter)
- 트리의 개수 : n_estimators
- 선택할 특징의 최대 수 : max_features
- 선택할 데이터의 시드 : random_state
랜덤 포레스트 특징
- 결정 트리 모델의 과대 적합을 통계적 방법으로 해소
- 결정 트리 모델처럼 쉽고 직관적임
- 부스팅 방식에 비해 빠른 수행 속도
- 모델 튜닝을 위한 시간이 많이 필요(하이퍼 파라미터의 종류가 많음)
- 큰 데이터 세트에도 잘 동작하지만 트리 개수가 많아질수록 시간이 오래 걸림
📌 AdaBoosting

- AdaBoost(adaptive boosting)
- Rf처럼 의사결정 트리 기반 모델의 종류 -> 각각의 트리들이 독립적으로 존재하지 않는다.
동작원리
- 가중치 부여(Weighting)
- 모든 데이터 포인트에 초기 가중치를 부여하고 동일한 가중치가 할당됩니다.
- 약한 학습기 학습(Weak Learner Training)
- 초기에 약한 학습으로 간단한 모델을 선택하고 학습을 진행합니다
- 약한 학습은 분류 작업을 수행하고, 분류가 잘못된 데이터 포인트에 더 큰 가중치를 부여합니다.
- 가중치 갱신(Weight Update)
- 학습된 약한 학습기의 성능을 기반으로, 각 데이터 포인트의 가중치가 조정됩니다.
- 잘못 분류된 데이터 포인트의 가중치가 증가하고 다음 약한 학습기가 더 잘 학습할 수 있도록 유도합니다.
- 약한 학습기 결합(Combining Weak Learners)
- 반복적으로 약한 학습기를 추가하고 가중치를 갱신하여 이전 학습기들과 결합합니다.
- 각각의 약한 학습기들은 이전 학습기의 성능에 따라 가중치가 부여되고 결합하여 강력한 학습기를 형성합니다.
📌 GradientBoosting(그래디언트)
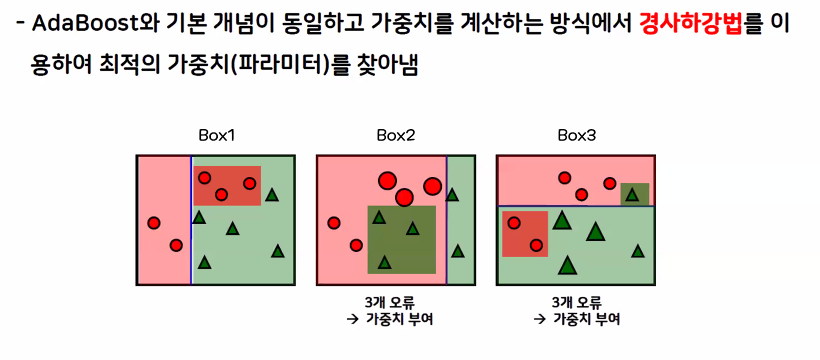
- 경사하강법을 이용한 부스팅입니다.
- AdaBoost와 기본 개념이 동일하고 가중치를 계산하는 방식에서 경사하강법을 이용하여 최적의 가중치(파라미터)를 찾아내는 방식입니다.
주요 매개변수(Hyperparameter)
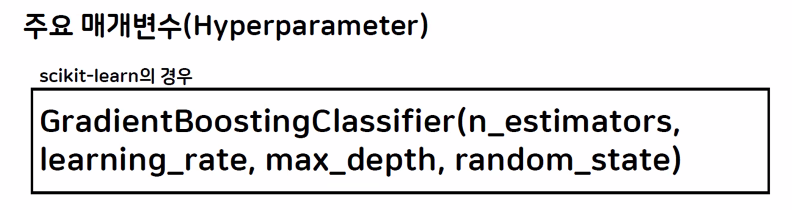
- 트리의 개수 : n_estimators
- 학습률 : learning_rate (높을수록 오차를 많이 보정)
- 트리의 깊이 : max_depth
- 선택할 데이터의 시드 : random_state
📌 XG 부스팅
XGBoost는 많은 특징을 가진 강력한 그래디언트 부스팅 중 하나입니다.
특징
- XGBoost는 빠른 속도와 높은 예측 성능을 제공하고 효율적인 알고리즘 기반으로 대용량 데이터 셋에서도 뛰어난 성능을 보입니다.
- Early Stopping 제공(학습이 더 이상 진행되지 않으면 학습을 종료)
- 과대 적합 방지를 위한 규제 포함
- 병렬로 빠른 학습이 가능
주요 매개변수(Hyperparameter)

- 트리의 개수 : n_estimators
- 학습률 : learning_rate
- 트리의 깊이 : max_depth
- 선택할 데이터의 시드 : random_state
📌 Light GBM
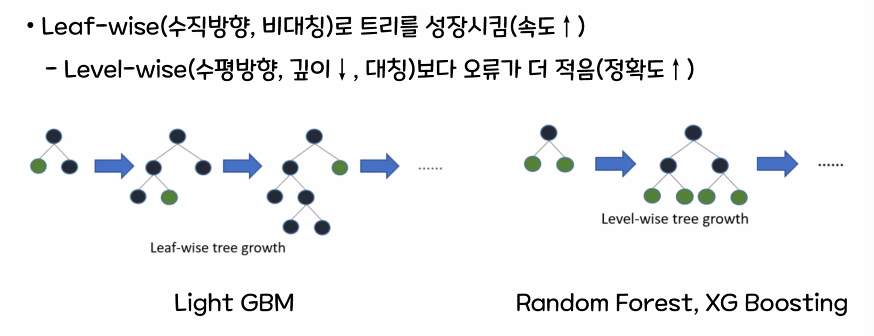
Light GBM은 그래디언트 부스팅 중 하나로 트리 기반 학습 방법을 사용하여 빠르고 효율적으로 대규모 데이터 셋에 대한 학습을 수행하는데 특화되어 있는 방식입니다.
장점
- XG_Boosting 보다 가벼워 2~10배의 속도(동일 파라미터 설정 시)
- 병렬 학습을 통해 예측 속도가 빠름(Leaf-wise 트리의 장점)
- 규제 및 조기 중단 가능합니다.
단점
- 소량의 데이터에서는 제대로 동작하지 않음(과대 적합 위험)
- Level-wise에 비해 과적합에 민감함
- 메모리 사용량이 높아 매우 큰 데이터에서 문제가 생길 수 있습니다.
- 하이퍼 파라미터가 매우 많아 조정하는데 어려움이 생길 수 있습니다.

여기까지 앙상블 모델 중에서 Bagging과 Boosting 모델의 종류였습니다!