안녕하세요!
오늘은 머신러닝에서 단일 모델에 비해 높은 성능과 신뢰성을 가진 Ensemble의 기본 개념과 종류에 대해 소개해 드려요.
📍 앙상블

앙상블 : 함께, 동시에 협력하여 등을 뜻하는 프랑스어
나무위키 출처
이러한 뜻을 가진 용어도 머신러닝에서 사용되는데요.
- 집단지성의 느낌으로 단일 모델에 비해 높은 성능과 신뢰성을 얻을 수 있어요.
- 적은 데이터양 대비 충분한 학습 효과를 거둘 수 있어요.
📌 앙상블 종류
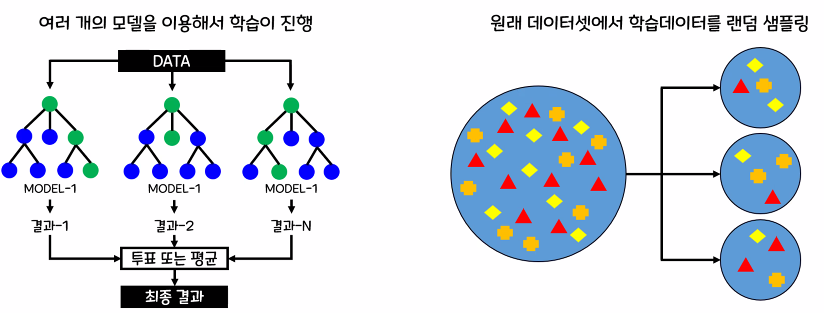
1. 보팅(Voting)
- 여러 개의 다른 종류의 모델이 예측한 결과를 투표 혹은 평균을 통해 최종 선정
2. 베깅(Bagging)
- 여러 개의 같은 종류의 모델이 예측한 결과를 투표 혹은 평균을 통해 최종 선정
- 대표 모델로는 Random Forest가 있어요
3. 부스팅(Boosting)
- 여러 개의 같은 종류의 모델이 순차적으로 학습, 예측하며 오류를 개선하는 방식(의사결정나무 모델)
- Ada Boosting, Gradient Boosting, XG Boosting, Light GBM이 있어요.
📌 배깅과 부스팅 차이
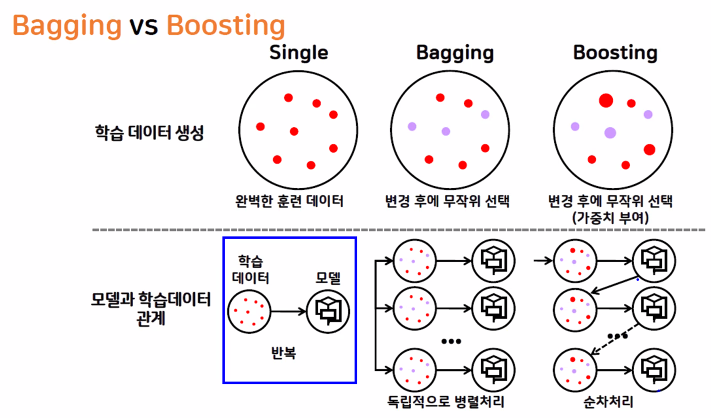
| 구분 | 배깅(Bagging) | 부스팅(Boosting) |
| 특징 | – 같은 종류의 모델이 투표를 통해 최종 예측 결과를 도출(데이터 샘플이 다르다) | – 순차 학습 + 예측(이전 모델의 오류를 고려) |
| 목적 | – 일반적으로 좋은 모델을 만들기 위해 – 과대적합 방지(편향된 학습을 방치) | – 맞추기 어려운 문제를 풀기 위함 – 과소적합 방지(부족한 학습을 방지) |
| 적합한 상황 | – 데이터 값들의 편차가 클 경우 | – 학습 정확도가 낮거나 오차가 클 경우 |
| 대표 모델 | – Random Forest | – Ada Boosting, Gradient Boosting, XG Boosting, Light GBM |
| 데이터 선택 | – 무작위 선택 | – 무작위 선택(오류 데이터에 가중치 적용) |
여기까지 앙상블의 기본 개념과 종류였습니다!
다음은 배깅과 부스팅의 여러 가지 모델에 대해 소개해 드리겠습니다!