안녕하세요! 오늘은 머신러닝의 과정 7가지에 대해 소개해드리겠습니다.
📌 머신러닝의 정의
우선 머신러닝은 컴퓨터 과학 분야에서 중요한 분야로, 컴퓨터 시스템에 데이터로부터 학습할 수 있는 능력을 부여하는 기술과 분야를 의미해요. 데이터에서 패턴을 발견하고, 이러한 패턴을 기반으로 예측, 분류, 군집 등의 작업을 수행하는 모델을 만드는 것이에요.
📍머신러닝의 과정 7가지
- 문제 정의
- 데이터 수집
- 데이터 전처리
- 데이터 분석
- 모델 선택
- 학습(훈련) 및 평가
- 배포
1. 문제 정의(Problem Definition)
먼저 모델을 어떻게 사용해서 이익을 얻을지 비즈니스 목적을 정의하는 과정을 말합니다. 어떤 문제를 해결할지, 어떤 데이터를 이용할지, 원하는 결과가 무엇인지 결정하는 현재 솔루션의 구성을 파악하는 단계예요. 이 과정에서 지도, 비지도, 강화 학습 중 어떤 학습을 선택할 것인지 고르는 단계입니다.
2. 데이터 수집(Data Collection)
다음은 문제 정의에서 정했던 필요한 데이터를 수집합니다. 데이터는 파일의 형식은 csv, xml, json의 형식을 가지기도 하고 데이터베이스에서 데이터를 수집하기도 합니다. 또 web 크롤링이나 iot 센서 데이터를 수집하는 등 다양한 방법으로 데이터를 수집합니다. 데이터는 매우 중요한 영향을 끼치기 때문에 데이터의 양과 품질을 많이 고려해야 해요.
3. 데이터 전처리(Data Preprocessiong)
데이터를 수집했을 때 나타나는 결측치와 이상치를 처리해야 합니다. 결측치는 데이터에서 누락된 부분으로 값이 0이 아닌 없는 값으로 Null로 나타나는 값을 말해요. 그리고 이상치는 유난히 높거나 낮은 값을 의미하는데 데이터의 분포에서 아주 멀리 떨어진 값을 말해요. 이러한 값들을 정제하고 정리하는 과정을 말하는데, 단위를 변환하는 scaling, 특성 엔지니어링 등이 포함됩니다.
4. 데이터 분석
데이터를 정제했다면 이 데이터를 가지고 기술적을 통계를 내고, 특성 간 상관관계를 파악합니다. Python의 pandas와 matplotlib의 함수를 이용해서 시각적으로 볼 수 있는 그래프를 만듭니다. 그다음 상관관계를 파악하여 모델의 매개 변수를 제거하는 조정을 거칩니다.
5. 모델 선택(Model Selection)
문제의 유형과 수집한 데이터에 따라 모델을 선택하게 되는데 비지도 학습, 지도학습, 강화 학습 등을 고려하여 목적에 맞는 적절한 모델을 선택합니다. KNN, SVM, Linear Regression, Lasso, Decision tree, Random forest 등이 있습니다. 그리고 하이퍼 파라미터를 조절하여 모델의 성능을 개선해 줍니다.
6. 모델 학습 및 평가(Model Training)
모델을 선택했다면 훈련 데이터를 입력하여 학습 시킵니다. model.fit(X_train, y_train) 함수를 사용하는데 여기에 학습용 문제 데이터인 X_train과 학습용 정답 데이터인 y_train 변수를 넣어줍니다. 그리고 학습을 마쳤다면 평가용 문제 데이터 X_test와, 평가용 정답 데이터인 y_train 변수를 넣어서 평가를 시키고 정확도, 정밀도, 재현율 등 모델의 성능을 평가합니다.
7. 모델 배포
평가를 마쳤다면 모델을 실제 환경에 배포하고 운영 환경에 통합하고 사용자가 모델의 결과를 활용할 수 있도록 만듭니다.
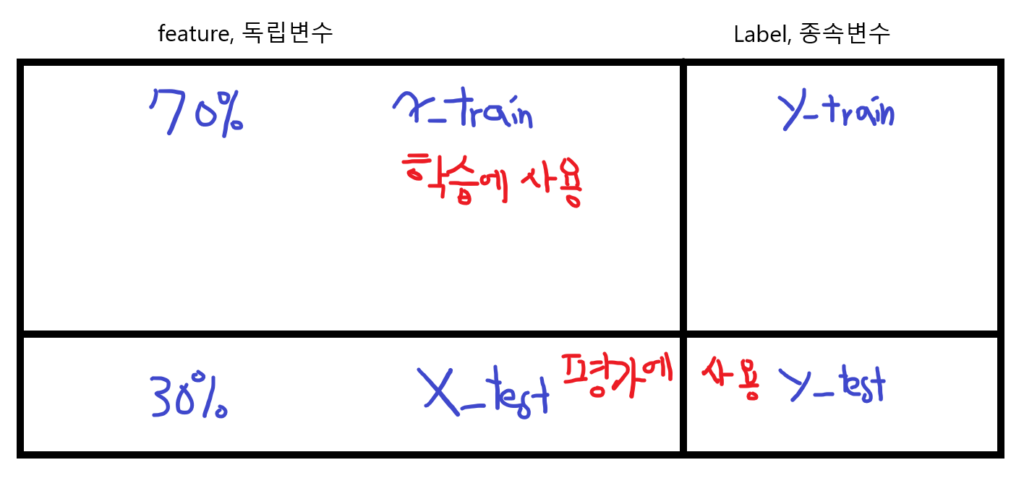
X_train,y_train이란?
수집한 데이터의 100% 중에서 학습을 위한 데이터와 평가용 데이터를 나눕니다. 비율은 7:3 정도로 나누면서 Feature의 독립변수와, Label 종속변수의 같은 비율로 나눕니다. 그리고 데이터를 변수에 담아 사용합니다.
지금까지 머신러닝의 과정 7가지에 대해 알아보았습니다.
다른 흥미로운 주제로 다시 오겠습니다!