안녕하세요!
오늘은 머신러닝의 개념 중 하나인 로지스틱 회귀 모델에 대해 알아보는 시간을 가져가 보겠습니다!
📍 로지스틱 회귀 모델

📌 로지스틱 회귀 모델이란?
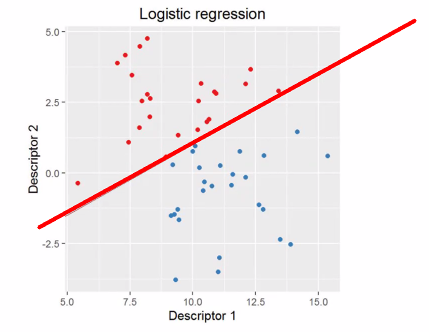
로지스틱 회귀 모델은 종속 변수가 이진 또는 범주형 데이터일 때 사용되는 통계적 분류 모델이에요.
선형 회귀 모델의 일종으로 독립 변수들의 가중합을 로지스틱 함수에 적용하여 확률 값을 예측하는 모델이에요.
주로 분류 문제에 사용되며 스팸 메일 여부 판별, 질병 발생 여부 등의 문제에 적용할 수 있는 모델 입니다.
📌 선형 모델 방식을 분류에 사용하는 이유
- 선형 모델은 간단한 함수식을 사용하기 때문에 학습 및 예측 속도가 빠르다.
- 매우 큰 데이터 세트에서도 잘 동작한다.
- 일반적으로 특성이 많을수록 더 잘 동작한다.
📌 선형 모델 방식의 한계점
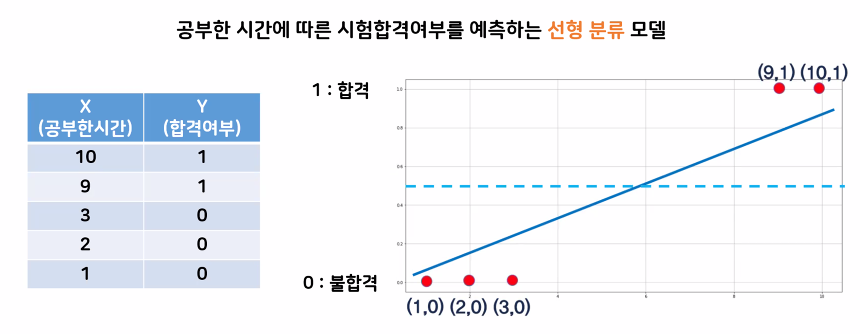
선형 직선의 해석은 다음과 같다.
- 이 그래프를 봤을 때 특정한 공부 시간 이상이 되면 합격이 되는 그래프
- 그 특정한 공부시간을 기준으로 합격의 1, 불합격의 0을 판별할 수 있음(점선이 기준선)
여기서 직선의 한계를 생각해 볼 수 있다.
- 선형 회귀 직선을 사용하여 분류하면 20시간을 공부했을 경우 y 값은 1보다 커지게 됨
- 출력되는 y 값이 특별한 의미가 없다고 함, 불 판단의 기준이 되기 힘듦
📌 sigmoid 함수
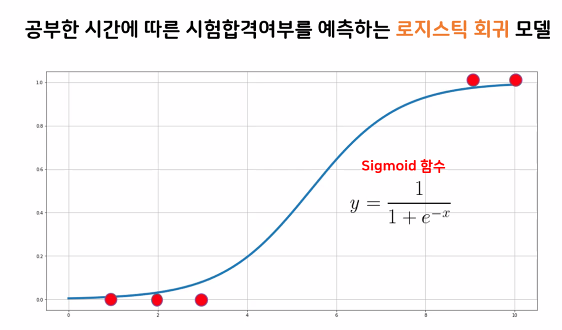
- 직선 대신 곡선을 사용하여 0 ~ 1 사이의 확률 정보로 표시가 가능해졌다.
- 기준선을 기준으로 낮으면 0, 높으면 1로 예측 가능
- 비선형 관계를 모델링 할 수 있다.
📌 sklearn LogisticRegression의 매개변수
Python
from sklearn.linear_model import LogisticRegression
LogisticRegression(C, max_iter)
# 규제 강도의 역수 : C
# (값이 작을수록 규제가 강해짐)
# max_iter
# (값을 크게 잡아 주어야 학습이 제대로 됨)
# 기본적으로 L2 규제 사용, 중요한 특성이 몇 개 없다면 L1 규제를 사용해도 무방
# (주요 특성을 알고 싶을 때 L1 규제를 사용하기도 한다)지금까지 로지스틱 회귀 모델에 대해 알아봤습니다!