안녕하세요!
오늘은 파이썬의 셀레니움으로 네이버 쇼핑몰 크롤링 해서 데이터를 정리해 보는 시간을 가져보겠습니다.

📍 네이버 쇼핑몰 크롤링

프로그램은 anaconda의 jupyter notebook으로 제작했습니다.
먼저 크롤링 할 페이지를 보고 오면 좋아요.
📌 필수 라이브러리
#쇼핑몰 크롤링 필수 라이브러리 설치
from selenium import webdriver # 셀레니움 라이브러리
from selenium.webdriver.common.by import By # 홈페이지 선택자를 가져오는 라이브러리
import time # 시간을 잠시 멈추기 위한 라이브러리
from selenium.webdriver.common.keys import Keys # 키
import pandas as pd
import numpy as np
import threading # 스레드 라이브러리
우선 크롤링을 위해 셀레니움을 가져왔고 쇼핑몰 크롤링에 가져올 정보들이 많아서 스레드를 이용하여 진행했습니다.
📌 크롬창 열기
# 크롬 열어주기
driver = webdriver.Chrome()
driver.get('https://shopping.naver.com/home')
# 찾고싶은 물건 입력
catagori = input("찾고 싶은 물건을 입력해주세요 : ")
try :
driver.get(f'https://search.shopping.naver.com/search/all?query={catagori}&frm=NVSHSRC&vertical=search')
time.sleep(1)
except(e):
print(e)크롬을 열고 네이버 쇼핑몰로 이동하는 코드입니다.
그리고 input에서 찾고 싶은 검색어를 입력해서 자동으로 검색이 됩니다.
📌 스레드 함수 정의
# 상품 내용 dictionary로 저장(elements)
# findElements 매게변수
#p_count = 현재 상품 index, 현재 상품 셀레니움 elements, 선택자 종류, 크롤링할 선택자
def findElements(p_count,j, By, selector):
for k in j.find_elements(By, selector):
# 공백 지우기
if k.text.strip() != "":
# 객체 나누기
content_split = k.text.split(":")
data[p_count][content_split[0]] = content_split[-1]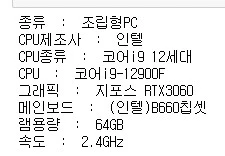
스레드를 사용하기 전에 적용시킬 함수를 정의해야 해요.
가장 많은 크롤링 시간이 생기는 상품 내용을 크롤링하는 코드에 적용시켜보겠습니다
여기서 크롤링하면 위 사진과 같은 결과가 나오는데 콜론을 기준으로 나눈 뒤 dictionary에 순차적으로 담는 함수입니다.
📌 크롤링 하기
# 쇼핑몰 크롤링하기
# 크롤링한 시간 세기
start_time = time.time()
# 크롤링 페이지 개수
count = 7
product_count = 0
data = []
# 입력된 페이지만큼 크롤링
for i in range(count):
# 페이지 맨 밑으로 스크롤 내리기
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(1)
# 모든 상품 크롤링
search_content_input = driver.find_elements(By.CLASS_NAME, 'product_info_area__xxCTi')
# 크롤링한 상품 개수 만큼 객체에 넣기
for j in search_content_input:
data.append({})
# 스레드로 상품정보 입력 함수
content = threading.Thread(target=findElements,args=(product_count,j,By.CSS_SELECTOR,'.product_desc__m2mVJ a'))
content.start()
# 이름, 가격, 등록날짜, 배송비 크롤링
title = j.find_element(By.CLASS_NAME,'product_title__Mmw2K').text
cost = j.find_element(By.CSS_SELECTOR,'.price_num__S2p_v em').text
delivery = j.find_element(By.CSS_SELECTOR,'.price_delivery__yw_We').text.split("\n")[-1]
regist = j.find_element(By.CSS_SELECTOR,'.product_etc__LGVaW:not(.linkAnchor)').text.split(" ")[-1]
# 크롤링한 내용 입력
data[product_count]['title'] = title
data[product_count]['cost'] = cost
data[product_count]['delivery'] = delivery
data[product_count]['regist'] = regist
content.join()
product_count+=1
# 다음 페이지
page = driver.find_element(By.CSS_SELECTOR,'.pagination_btn_page___ry_S.active + a')
print('성공페이지', int(page.text)-1)
page.click()
time.sleep(1)
end_time = time.time()
# 크롤링 걸린 시간
print("초", end_time - start_time)

검색 결과 창에서 페이지의 모든 상품을 한 개씩 순차적으로 크롤링을 하고 그 내용을 dictionary로 담는 코드입니다.
스레드를 사용한 코드와 사용하지 않는 코드의 속도는 14% 정도 차이가 났습니다!
그럼 쇼핑몰 크롤링 한 데이터가 모두 data에 담겼습니다.
📌 결과 확인
모든 크롤링이 끝났습니다.
이제 데이터들을 확인해 봐야겠죠?


data의 객체에는 다양한 정보들이 들어있는데 여기서 객체마다 들어있는 key 값이 엄청 다양하게 들어있어요.
그래서 DataFrame을 만들어서 확인해 본 결과 총 280개의 결과가 나왔고, 상품 내용이 64종 있었어요.
여기에서 값이 한 개만 있는 key 값이 많았고 이러한 내용들을 제거해야 데이터를 깨끗하게 볼 수 있을 것 같아요.
📌 불필요한 데이터 key 제거하기
## 데이터 제거하기
# 데이터 프레임 들기
data_df = pd.DataFrame(data)
# 모든 칼럼
for i in data_df.columns:
# 칼럼 데이터가 10개 이하인 칼럼 제거하기
if data_df[i].count() < 10:
del data_df[i]
data_df.info()
먼저 데이터 프레임을 만들고 칼럼을 가져옵니다.
저는 칼럼 안에 있는 데이터 개수가 10개 미만인 것들을 제거했지만 조건문에 있는 숫자를 바꿔서 제거할 칼럼을 조절할 수 있습니다.
제거 한 후에 확인한 결과 64개에서 24개로 확 줄었습니다.
📌 칼럼 정리하기
# 칼럼 데이터 많은 순으로 정렬하기
sortcolumn = {}
# 칼럼 : 데이터 개수 dictionary로 만들기
for i in data_df.columns:
sortcolumn.update({i : data_df[i].count()})
# 칼럼 데이터 많은 순으로 정렬
sortcolumn = sorted(sortcolumn.items(), key=lambda x:x[1],reverse=True)
# 데이터 key 값만 추출하기
sortcolumn_key = [x[0] for x in sortcolumn]
sortcolumn_key
# Nan 뒤로 빼기
data_df_final = pd.DataFrame(data,columns=sortcolumn_key)
data_df_final.sort_values(by='CPU제조사 ', na_position='last', ignore_index=True)이제 칼럼의 데이터가 많은 순으로 정렬하고 마무리하겠습니다!
먼저 dictionary로 ‘칼럼 : 개수’로 변환하고 개수 순으로 정렬했습니다.
여기에서 key 값 이름이 모두 다르기 때문에 lambda 함수를 이용하여 정렬했습니다.
마지막으로 정렬된 칼럼으로 DataFrame을 만들고 가장 많은 내용인 CPU 제조사를 기준으로 빈 데이터들을 맨 뒤로 정렬했습니다.
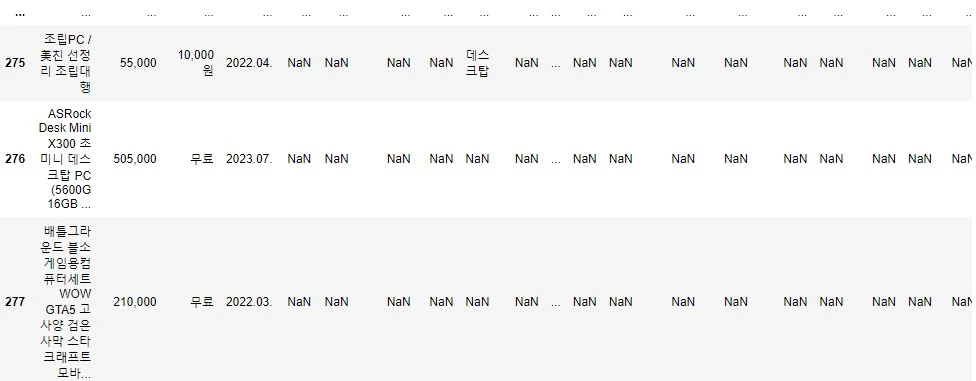
여기까지 네이버 쇼핑몰 크롤링을 셀레니움으로 하는 프로그램이었습니다.
다음에도 좋은 정보로 찾아뵙겠습니다.
셀레니움으로 네이버 항공권 자동으로 검색하기 1편 python